很早就想梳理一下关于Diffusion Model的相关知识,试图不再“畏惧”那一大堆数学公式
本文将基于Google Research, Brain Team在2022年的一篇综述文章《Understanding Diffusion Models: A Unified Perspective》https://arxiv.org/abs/2208.11970 ,逐步展开理解DDPM、DDIM等Diffusion Models所需要的一些数学知识。
生成式模型
Given observed samples x from a distribution of interest, the goal of a generative model is to learn to model its true data distribution p(x). Once learned, we can generate new samples from our approximate model at will. Furthermore, under some formulations, we are able to use the learned model to evaluate the likelihood of observed or sampled data as well.
这一段话给出了生成式模型的一个定义,即“从样本数据分布中学习到真实数据分布,并可以从学习到的真实数据分布中采样出新的样本”。这里的从样本数据分布中学习到真实数据分布,其实也就是数理统计中参数估计的过程,因为我们通常会假设真实数据分布满足一个高斯分布律,那么从样本数据分布中学习到真实数据分布也就是对这个高维高斯分布的参数进行估计的过程。
There are several well-known directions in current literature, that we will only introduce briefly at a high level. Generative Adversarial Networks (GANs) model the sampling procedure of a complex distribution, which is learned in an adversarial manner. Another class of generative models, termed "likelihood-based", seeks to learn a model that assigns a high likelihood to the observed data samples. This includes autoregressive models, normalizing flows, and Variational Autoencoders (VAEs). Another similar approach is energy-based modeling, in which a distribution is learned as an arbitrarily flexible energy function that is then normalized.
这里提到GAN与VAE两种方法,GAN(生成对抗网络)是利用了对抗的方法对采样过程进行建模,用一个神经网络直接去拟合真实分布,优化目标是使得真实数据分布与生成数据分布的KL散度达到最小。
而VAE则是基于极大似然估计的方法,神经网络的优化目标是使得样本数据分布出现的概率最大。
这里只是给出了定性的理解,并没有给出公式(真要写公式还挺复杂的hhh)
Score-based generative models are highly related; instead of learning to model the energy function itself, they learn the score of the energy-based model as a neural network. In this work we explore and review diffusion models, which as we will demonstrate, have both likelihood-based and score-based interpretations. We showcase the math behind such models in excruciating detail, with the aim that anyone can follow along and understand what diffusion models are and how they work.
这里提及了一下score-based模型,对于score-based方法,我并不是太了解,不过diffusion model是可以从likelihood-based与score-based两种角度解读的。其中DDPM的原论文就是通过likelihood-based方法推导公式,而Score-Based Generative Modeling through Stochastic Differential Equations(arxiv: https://arxiv.org/abs/2011.13456) 则是通过随机微分方程(SDE)的方式完成了score-based的角度解读。
从AutoEncoder开始
在wikipedia上,https://en.wikipedia.org/wiki/Autoencoder ,AE的作用是学习对高维度数据做低维度“表示”(“表征”或“编码”);因此,通常用于降维。利用AE学习到的encoder对数据进行编码,将x(一般是图片)从高维空间Rw×h编码(降维)到latent code z(一个特征向量)低维空间Rn,一般n≪w×h。
这实际上包含一种洞见,即我们所看到的样本数据,实际包含了大量的冗余信息。我们实际上可以通过寻找样本空间X的一个子空间Z,即构造一个映射Eϕ:X→Z,完成对高维度数据做低维度“表示”。其中映射Eϕ称作编码器,ϕ为该编码器的参数。
为了找到这个编码器Eϕ,我们有多种方法,但归根结底都可以表示成对proxy task的优化。例如,我们可以假设将该编码器Eϕ所得到的latent code z用于图像分类任务应该具有较好的表现,也就是说将proxy task设置为image classification。那么我们可以构造一个分类器Dθ:Z→L,其中L为预测label的取值空间。为了优化这个proxy task,我们使用梯度下降法对样本label真实分布L^与预测label的取值分布L的交叉熵进行优化,也就是
ϕ,θargmin(−∫XL^(x)logDθ(Eϕ(x))dx)
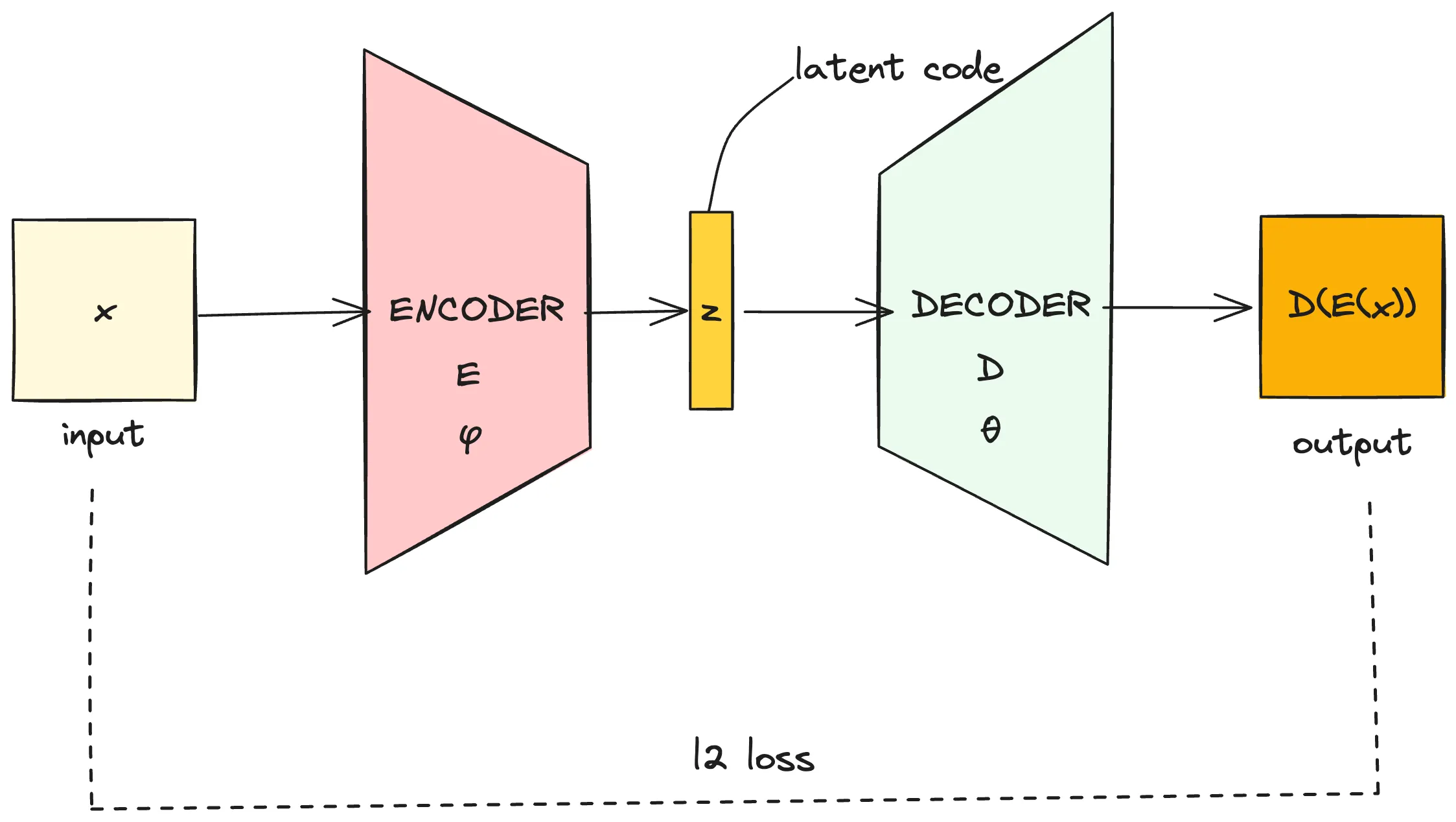
对于AutoEncoder,最理想的proxy task是完全恢复输入的样本信息,也就是无损降维。具体来说,我们期望映射Dθ可以完成Dθ:Z→X,将latent code z重新恢复为Eϕ输入的x。为了优化这个reconstruction task,我们一般使用L2损失,也即
ϕ,θargmin(−∫X∥x−Dθ(Eϕ(x))∥2dx)
使用神经网络作为编码器与解码器,那么AE可以用下图(使用excalidraw绘制)表示
VAE——变分自编码器
VAE的原论文是Auto-Encoding Variational Bayes(arxiv: https://arxiv.org/abs/1312.6114v11)
首先我们看看VAE的网络架构
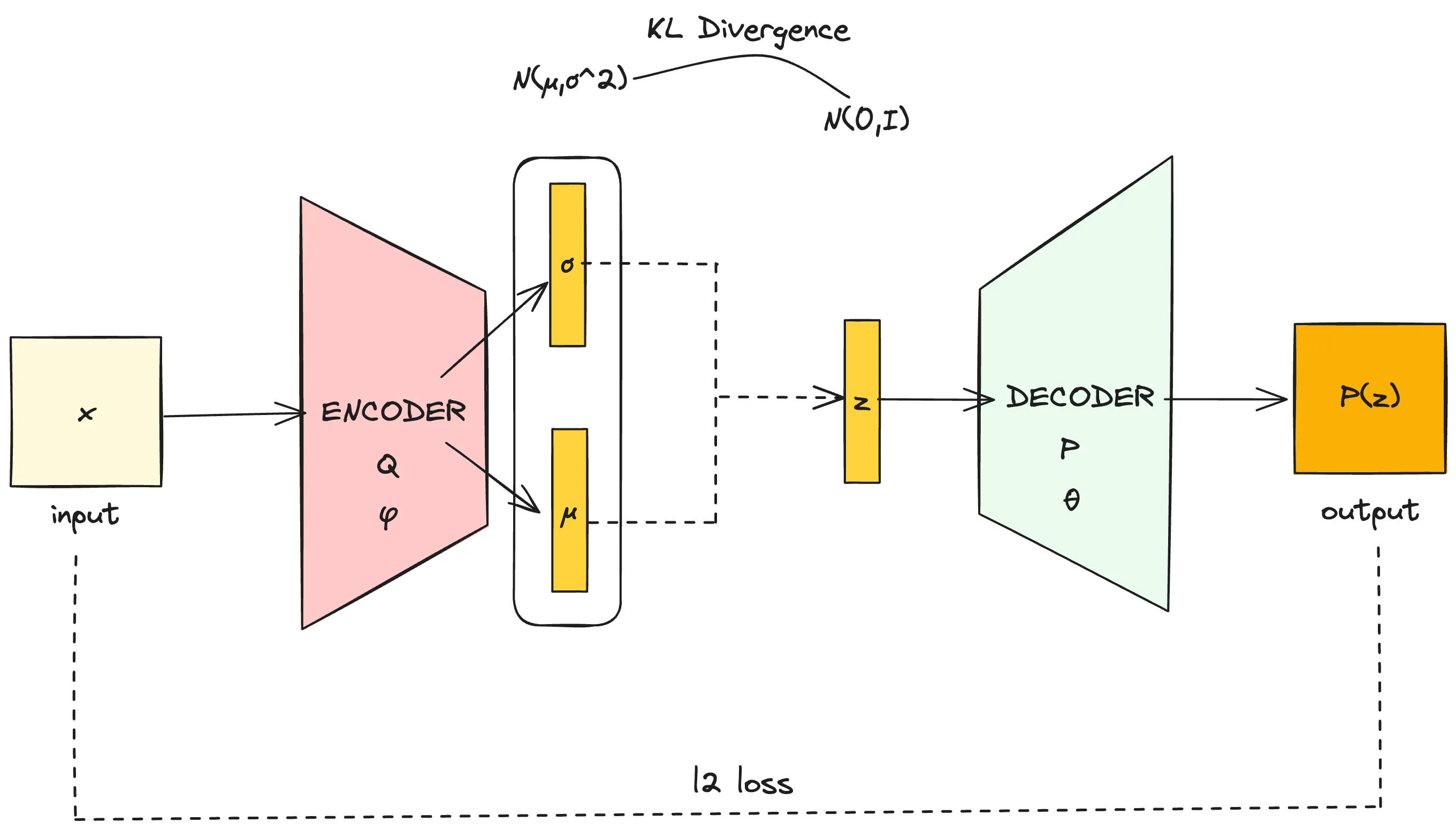 这个网络结构跟AE基本完全一样,只是Encoder部分的输出是一组σ参数与μ参数,从由这两个参数决定的高斯分布N(μ,σ2)中采样出隐变量z作为decoder的输入。损失函数部分,除了L2损失以外额外加入了分布N(μ,σ2)对分布N(0,I)的KL散度。
这个网络结构跟AE基本完全一样,只是Encoder部分的输出是一组σ参数与μ参数,从由这两个参数决定的高斯分布N(μ,σ2)中采样出隐变量z作为decoder的输入。损失函数部分,除了L2损失以外额外加入了分布N(μ,σ2)对分布N(0,I)的KL散度。
首先,可以肯定的是,VAE与AE之间肯定会存在着十分紧密的关系。但我们会想,VAE将encoder直接编码隐变量z变为encoder输出一个高斯分布,从高斯分布中采样一个隐变量是为了什么呢?
让我们回到生成式模型的目标,生成式模型的目标是从估计的真实数据分布中采样得到新的样本,也就是说,当我们确定隐变量z满足的分布p(z)时,从p(z)中任意采样一个z,经过decoder得到的p(x∣z)都应该是有意义的新样本。通俗来说,这要求我们任取一个z,decoder都能恢复出一个清晰的有意义的图像。而AE模型则无法完成上述要求,从实验结果来看,对于随机采样的一个z,AE的decoder恢复出的图像大多是模糊的无意义的乱码。这是因为由于只存在L2重建损失且encoder直接完成对隐变量z的编码,z的分布p(z)会被过度压缩(过度降维),导致p(z)只分布在一个很小的流形上。而在p(z)之外的随机采样则无法获得有效的重建结果。
为了解决上述不足,VAE做出了一个先验假设,即隐变量z的分布p(z)∼N(0,I),或记作p(z)=N(z;0,I)。并让encoder完成对z分布的点估计。
我们记encoder为qϕ(z∣x),表示给定x的条件下,z的估计分布。decoder为pθ(x∣z),表示给定z的条件下,x的估计分布。
回忆生成式模型的优化目标,我们要使得样本数据分布出现的概率最大。即使得p(x)最大。采用极大对数似然法,优化目标可以写作logp(x)
由于
logp(x)=logp(x)∫qϕ(z∣x)dz(概率的归一性)=∫qϕ(z∣x)(logp(x))dz=Eqϕ(z∣x)[logp(x)](Law of the unconscious statistician)=Eqϕ(z∣x)[logp(z∣x)p(x,z)](链式法则)=Eqϕ(z∣x)[logp(z∣x)qϕ(z∣x)p(x,z)qϕ(z∣x)]=Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)]+Eqϕ(z∣x)[logp(z∣x)qϕ(z∣x)]=Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)]+DKL(qϕ(z∣x)∣∣p(z∣x))(KL散度的定义)≥Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)](KL散度大于0)
我们记Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)]为ELBO(Evidence Lower Bound)。
下面将说明,对ELBO的优化,也即是对logp(x)下界的优化,是一个合适的proxy optimization objective。
由于logp(x)=Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)]+DKL(qϕ(z∣x)∣∣p(z∣x)),注意这里的p(x)、p(x,z)、p(z∣x)都是真实分布,是一个固定的分布,整个优化目标可以写作
ϕargmaxlogp(x)=Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)]+DKL(qϕ(z∣x)∣∣p(z∣x))
当调整ϕ时,总能通过优化ELBO使得DKL(qϕ(z∣x)∣∣p(z∣x))=0,这样ELBO就达到logp(x)这一上界。
上述过程称作变分贝叶斯估计(Variational Bayes)。
下面,我们将引入解码器pθ(x∣z)作为对p(x∣z)的估计。
Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)]=Eqϕ(z∣x)[logqϕ(z∣x)pθ(x∣z)p(z)]=Eqϕ(z∣x)[logpθ(x∣z)]+Eqϕ(z∣x)[logqϕ(z∣x)p(z)]=Eqϕ(z∣x)[logpθ(x∣z)]−DKL(qϕ(z∣x)∣∣p(z))
称Eqϕ(z∣x)[logpθ(x∣z)]为重建项,DKL(qϕ(z∣x)∣∣p(z))为先验匹配项。那么,优化ELBO也就是使得重建项尽量大而先验匹配项尽量小。具体来说,也就是让qϕ(z∣x)与p(z)的分布尽量靠近,前面我们提到,p(z)的分布我们假设是服从p(z)∼N(0,I)。而重建项的含义为,在给定qϕ(z∣x)的情况下(encoder已经完成编码),pθ(x∣z)的值要尽量的大(decoder要尽量恢复重建出x)
现在,我们可以理解VAE的网络结构图了,在AE的基础上,让encoder输出一组均值与方差,使得qϕ(z∣x)尽量与p(z)=N(z;0,I)靠近,而给定x时,通过qϕ(z∣x)得到隐变量z,使用decoder完成图像重建,并使用L2损失。
HVAE