目录
2023年7月26日,Stability. AI 发布了SDXL 1.0模型,声称可以达到媲美midjourney的水平。
SDXL 1.0拥有目前所有开放式图像模型中最大的参数数量,采用了创新的新架构,包括一个拥有35亿参数的基础模型和一个66亿参数的优化模型。
截止到本篇blog发出时间,civitai网站上各种以SDXL 1.0 model为base model的checkpoint与LoRA也已经大量出现,但control net生态还尚未发展完全,下面将对SDXL模型进行一些评测。

什么是SDXL1.0?下面是来自Hugging Face的一段介绍
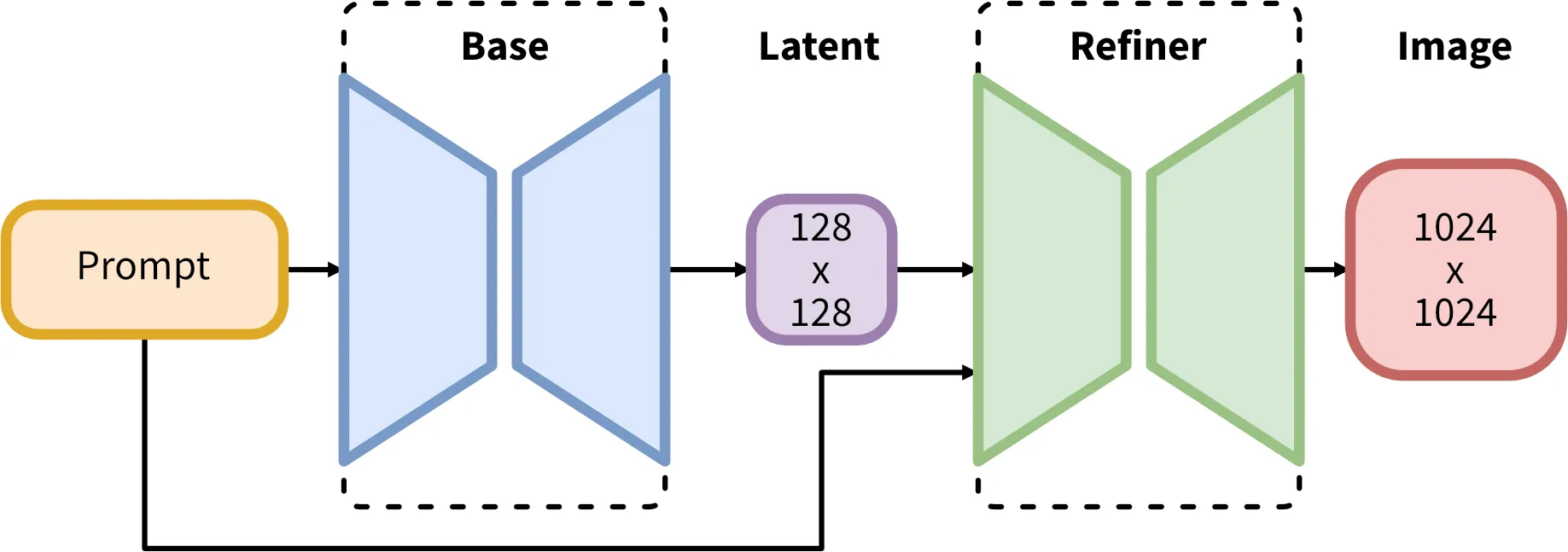 SDXL consists of an ensemble of experts pipeline for latent diffusion: In a first step, the base model is used to generate (noisy) latents, which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps. Note that the base model can be used as a standalone module.
SDXL consists of an ensemble of experts pipeline for latent diffusion: In a first step, the base model is used to generate (noisy) latents, which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps. Note that the base model can be used as a standalone module.
Alternatively, we can use a two-stage pipeline as follows: First, the base model is used to generate latents of the desired output size. In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (https://arxiv.org/abs/2108.01073, also known as "img2img") to the latents generated in the first step, using the same prompt. This technique is slightly slower than the first one, as it requires more function evaluations.
Source code is available at https://github.com/Stability-AI/generative-models .
Model Description Developed by: Stability AI Model type: Diffusion-based text-to-image generative model License: CreativeML Open RAIL++-M License Model Description: This is a model that can be used to generate and modify images based on text prompts. It is a Latent Diffusion Model that uses two fixed, pretrained text encoders (OpenCLIP-ViT/G and CLIP-ViT/L). Resources for more information: Check out our GitHub Repository and the SDXL report on arXiv.
可以看到,SDXL对比与之前的SD1.5模型,多了Refiner这一步骤,因此在调用逻辑上也存在一定差别,在最新版SD-WEBUI上,可以看到多出了refiner的选择,常用设置是前80%step采用base model进行生成,而后20% step采用refiner model进行refine。
SD-XL 1.0-base Model各种风格的测试
由于SDXL模型对比之前SD1.5模型参数量更大,所以有一个显著的区别就是,以前在SD1.5模型中需要使用LoRA才能较好调控的风格,现在SDXL只需要合适的提示词就可以实现一个较为精准的控制。
较为流行的一个插件是https://github.com/ahgsql/StyleSelectorXL ,这个插件提供了多种风格,每个风格对应一段提示词模板,目前一共有77种风格。
这77种风格的json配置文件如下,插件会自动将正向提示词替换为prompt域,反向提示词替换为negative_prompt域。
https://github.com/ahgsql/StyleSelectorXL/blob/main/sdxl_styles.json
下面我将采用prompt为
An astronaut riding a white horse, art by Vincent van Gogh,
对上述77种风格分别进行生成,结果为:
| 风格 | 生成结果 | 风格 | 生成结果 |
|---|---|---|---|
| base |  | 3D Model |  |
| Analog Film |  | Anime |  |
| Cinematic |  | Comic Book |  |
| Craft Clay |  | Digital Art |  |
| Enhance |  | Fantasy Art |  |
| Isometric Style |  | Line Art |  |
| Lowpoly |  | Neon Punk |  |
| Origami |  | Photographic |  |
| Pixel Art |  | Texture |  |
| Advertising |  | Food Photography |  |
| Real Estate |  | Abstract |  |
| Cubist |  | Graffiti |  |
| Hyperrealism |  | Impressionist |  |
| Pointillism |  | Pop Art |  |
| Psychedelic |  | Renaissance |  |
| Steampunk |  | Surrealist |  |
| Typography |  | Watercolor |  |
| Fighting Game |  | GTA |  |
| Super Mario |  | Minecraft |  |
| Pokémon |  | Retro Arcade |  |
| Retro Game |  | RPG Fantasy Game |  |
| Strategy Game |  | Street Fighter |  |
| Legend of Zelda |  | Architectural |  |
| Disco |  | Dreamscape |  |
| Dystopian |  | Fairy Tale |  |
| Gothic |  | Grunge |  |
| Horror |  | Minimalist |  |
| Monochrome |  | Nautical |  |
| Space |  | Stained Glass |  |
| Techwear Fashion |  | Tribal |  |
| Zentangle |  | Collage |  |
| Flat Papercut |  | Kirigami |  |
| Paper Mache |  | Paper Quilling |  |
| Papercut Collage |  | Papercut Shadow Box |  |
| Stacked Papercut |  | Thick Layered Papercut |  |
| Alien |  | Film Noir |  |
| HDR |  | Long Exposure |  |
| Neon Noir |  | Silhouette |  |
| Tilt-Shift |  |
SD-XL 1.0-base Model进行人像风格化的测试
下面的测试将用到一些网络来源图片,如有侵权,请联系我删除!
我们采用 CounterfeitXL模型作为生成的基模
- 目标:将真实照片转为固定画风,而较好保留真实照片的构图
- 输入:

- 输出:该图片风格化结果
测试流程如下:
-
使用CLIP进行关键词推理
结果
a woman with long hair and a bow tie standing in front of a train station with a train in the background, a character portrait, Du Qiong, side profile, aestheticism -
修改CLIP推理结果中不正确的部分
删除掉
Du Qiong这个词 -
设定长宽,原图为
4096x2304,这么大的分辨率会VRAM不够,我们可以进行等比缩小,但最好保持在1080p以上,这里我选择了2048x1152 -
调整重绘幅度,我们选择
0.3左右的值就可以了,不宜太高 -
选择一个风格,如
Anime -
出图
结果:

可以看到这个结果质量还是相当不错的,除了左侧的背景虚化糊成一团导致整体画面左侧较空,整体画面不太平衡以外,这个出图质量在如此一个不复杂的setting下已经相当满足需求了,更为重要的是,上面的测试是一次出图的,没有经过抽卡挑选的过程,这也是SDXL模型给我的惊喜之一,稳定性真的很高。
再尝试一组输入吧~
- 输入:

- 输出:

可以看到脸部有点没生成好,其余的细节还是相当不错的,还是固定住上面这次生成的随机种子,加上After Detailer插件改善人脸试试吧~
输出: 
可以看到确实改善了人脸生成,但是也出现了明显的人脸区域的框框,还是存在较大的提升空间哈~(低情商:算了生成出shit了。多抽几次吧)
用第一张测试图片,试一试别的画风~
注意,有些画风与这张图片的构图相性不和,可能需要拉高重绘幅度才能较好展现画风,而拉高重绘幅度又会影响画面的构图,所以在control net没有成熟之前还是选择合适的画风吧。
| 画风 | 结果 |
|---|---|
| Anime | |
| Papercut Collage |  |
| Cinematic |  |
| Minecraft |  |
| Disco |  |
| Neon Noir |  |
本文作者:insomnia
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!